Human-AI Learning System · First vertical proof: Trading Brain
A learning system
for humans and AI
to think better together
NOUS OS connects human intent, learning notes, verified memory, agent routing, outcome proof, and human authority —
with Trading Brain as the first vertical proof and production hardening in progress.
Hermes / Aria = human intent layer
Obsidian = knowledge sedimentation
TrustMem = verified memory
Synapse = event mesh
trading-agent = first runtime proof
NOUS OS = a human-AI learning system: human intent + readable notes + verified memory + agent coordination + measured outcomes + human authority.
North Star V2
A verifiable learning loop
The system connects intent, operating notes, durable memory, event routing, runtime truth, and outcome proof into a repeatable learning loop.
Authority boundary
Human judgment stays final
NOUS OS can route, recall, score, and brief. It cannot bypass irreversible broker, risk, reconciliation, approval, or live-state boundaries.
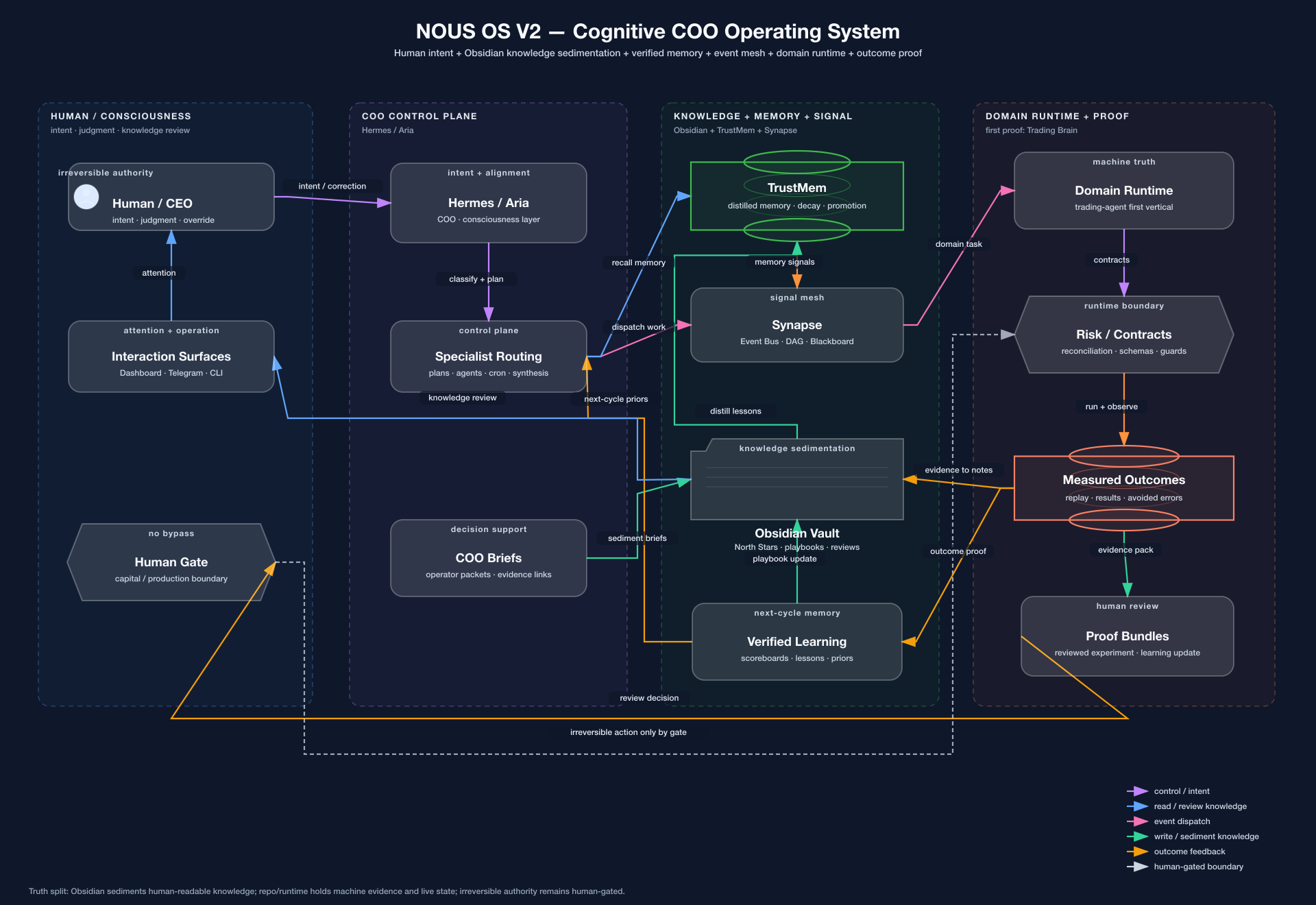
Architecture map: Human -> Hermes / Aria -> Obsidian + TrustMem + Synapse -> domain runtime -> outcome proof.
Generated with Fireworks Tech Graph · review-only